Featured Articles
New MLPerf Training and HPC Benchmark Results Showcase 49X Performance Gains in 5 Years
New benchmarks, new submitters, performance gains, and new hardware add scale to latest MLCommons MLPerf results

MLCommons Announces the Formation of AI Safety Working Group
The initial focus will be on the development of safety benchmarks for large language models used for generative AI — using Stanford’s groundbreaking HELM framework.

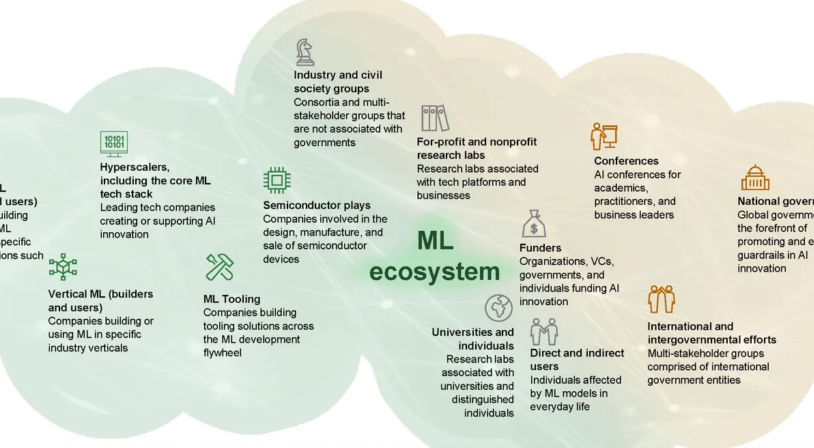
Perspective: Unlocking ML requires an ecosystem approach
Factories need good roads to deliver value
Blog
-

Announcing the MLCommons AlgoPerf Training Algorithms Benchmark Competition
Accelerating neural network training through algorithmic improvements
-
MLCommons at ICML 2023
Join our a data-centric ML research workshop, LLM panel, and the MLCommons Data Underground Social
-
Perspective: Unlocking ML requires an ecosystem approach
Factories need good roads to deliver value
News
-
Announcing the MLCommons AlgoPerf Training Algorithms Benchmark Competition
Accelerating neural network training through algorithmic improvements
-
New MLPerf Training and HPC Benchmark Results Showcase 49X Performance Gains in 5 Years
New benchmarks, new submitters, performance gains, and new hardware add scale to latest MLCommons MLPerf results
-
MLCommons Announces the Formation of AI Safety Working Group
The initial focus will be on the development of safety benchmarks for large language models used for generative AI — using Stanford’s groundbreaking HELM framework.